

Измер. производит.



AIDA64 содержит несколько тестов, которые можно использовать для оценки производительности отдельных частей оборудования или системы в целом. Это синтетические тесты, то есть они могут оценить теоретическую максимальную производительность системы. Тесты пропускной способности памяти, центрального процессора или FPU-блоков основаны на многопотоковом механизме тестирования AIDA64, который поддерживает до 640 одновременных потоков обработки и 10 групп процессоров (начиная с версии AIDA64 Business 4.00). Данный механизм обеспечивает полную поддержку для мультипроцессоров (SMP), многоядерных и гиперпотоковых технологий.
Тестирование производительности кэша и дисков
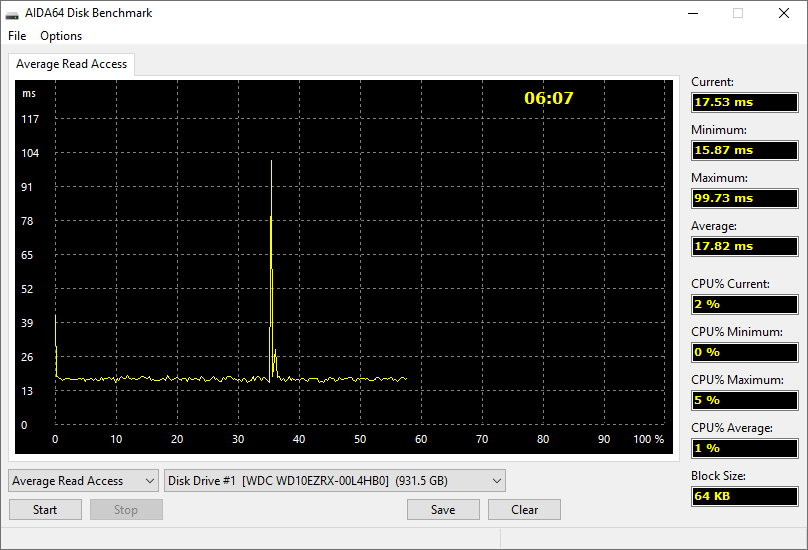
AIDA64 предлагает также отдельные тесты для оценки пропускной способности считывания, записывания и копирования, а также задержки кэша процессора и системной памяти. Также существует отдельный тестовый модуль для оценки производительности накопительных устройств, в том числе жестких дисков (S)ATA или SCSI, RAID-массивов, оптических дисков, SSD-накопителей, USB-накопителей и карт памяти.
Тестирование производительности GPGPU
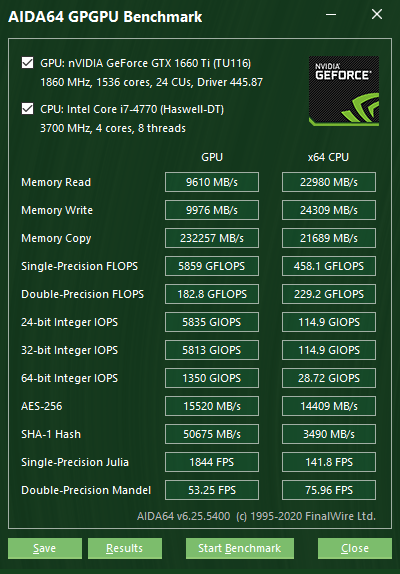
Данная тестовая панель, доступ к которой можно получить в разделе меню Сервис | Тест GPGPU, предлагает набор тестов производительности OpenCL GPGPU. Они разработаны для оценки вычислительной производительности GPGPU при помощи различных нагрузок OpenCL. Каждый отдельный тест можно выполнить максимум на 16 графических процессорах, включая процессоры AMD, Intel и NVIDIA, или их комбинации. Конечно же, полностью поддерживаются конфигурации CrossFire и SLI, а также dGPU и APU. В общем, данная функция позволяет протестировать производительность практически любого вычислительного устройства, которое представлено как графический процессор среди устройств OpenCL.
Кроме комплексных тестов производительности, AIDA64 предлагает специальные микротесты — их можно найти в разделе «Тесты» в меню «Страница». Благодаря исчерпывающей справочной базе данных результатов, результаты тестирования производительности можно сравнить с аналогичными показателями по другим конфигурациям. На данный момент доступны следующие микротесты:
Тестирование производительности памяти
Тесты производительности памяти оценивают максимально возможную пропускную способность при выполнении определенных операций (чтение, запись, копирование). Они написаны на языке ассемблера и максимально оптимизированы для всех популярных вариантов ядер процессоров AMD, Intel и VIA путем применения соответствующих расширений набора команд x86/x64, x87, MMX, MMX+, 3DNow!, SSE, SSE2, SSE4.1, AVX и AVX2.
Тест задержки памяти оценивает типичную задержку при считывании центральным процессором данных из системной памяти. Задержка памяти — это время для предоставления данных в регистре целочисленной арифметики центрального процессора после выдачи команды считывания.
CPU Queen

Этот простой целочисленный тест оценивает возможности предсказания ветвлений центрального процессора и ошибочного прогнозирования ветви. Он вычисляет решения для классической головоломки с восемью ферзями, размещенными на шахматной доске 10х10. Теоретически, при одинаковой тактовой частоте, процессор с более коротким конвейером и меньшими накладными расходами в случае ошибочного предположения о ветвлении может показать более высокие результаты теста. Например, если отключить гиперпотоковость, процессоры Pentium 4 на базе Intel Northwood получат более высокие баллы, чем центральные процессоры Intel Prescott, поскольку в первых присутствует 20-ступенчатый конвейер, а в последних — 31-ступенчатый. CPU Queen использует целочисленные оптимизации MMX, SSE2 и SSSE3.
CPU PhotoWorxx

Данный целочисленный тест оценивает производительность центрального процессора при помощи нескольких алгоритмов обработки двухмерных фотографий. Он выполняет следующие задачи c довольно крупных RGB-изображениях:
- заполнение изображения пикселями случайно выбранного цвета;
- поворот изображения на 90 градусов против часовой стрелки;
- поворот изображения на 180 градусов;
- дифференцирование изображения;
- преобразование пространства цветов (используется, например, при преобразовании JPEG).
Тест, в основном, предназначен для блоков выполнения операций целочисленной арифметики SIMD-архитектуры центрального процессора и подсистем памяти. Тест CPU PhotoWorxx использует соответствующие расширения наборов команд x87, MMX, MMX+, 3DNow!, 3DNow!+, SSE, SSE2, SSSE3, SSE4.1, SSE4A, AVX, AVX2, и поддерживает NUMA, гиперпотоковость, мультипроцессоры (SMP) и многоядерность (CMP).
CPU ZLib
Данный целочисленный тест оценивает комбинированную производительность центрального процессора и подсистемы памяти при помощи свободной библиотеки для сжатия данных ZLib. ЦП ZLib использует только основные инструкции x86, но поддерживает гиперпотоковость, мультипроцессоры (SMP) и многоядерность (CMP).
CPU AES
Этот целочисленный тест оценивает производительность центрального процессора при выполнении шифрования по криптоалгоритму AES. В шифровании AES — это симметричный алгоритм блочного шифрования. Сегодня AES используется в нескольких инструментах сжатия, таких как 7z, RAR, WinZip, а также в программах шифрования BitLocker, FileVault (Mac OS X), TrueCrypt. CPU AES использует соответствующие инструкции x86, MMX и SSE4.1, он является аппаратно ускоренным на процессорах VIA C3, VIA C7, VIA Nano и VIA QuadCore, поддерживающих технологию VIA PadLock Security Engine, а также на процессорах, поддерживающих расширение наборов команд Intel AES-NI. Данный тест поддерживает гиперпотоковость, мультипроцессоры (SMP) и многоядерность (CMP).
CPU Hash
Этот целочисленный тест оценивает производительность центрального процессора при выполнении алгоритма кэширования SHA1 согласно Федеральному стандарту обработки информации 180-4. Код для этого теста написан на языке ассемблера, он оптимизирован для большинства популярных вариантов ядер процессоров AMD, Intel и VIA путем применения соответствующих расширений набора команд MMX, MMX+/SSE, SSE2, SSSE3, AVX, AVX2, XOP, BMI и BMI2. Тест CPU Hash является аппаратно ускоренным на процессорах VIA C7, VIA Nano и VIA QuadCore, поддерживающих технологию VIA PadLock Security Engine.
FPU VP8
Этот тест измеряет производительность сжатия видео кодеком Google VP8 (WebM) версии 1.1.0. Происходит кодирование за 1 проход видеопотока с разрешением 1280x720 («HD ready ») и скоростью 8192 кбит/с при максимальных настройках качества. Содержимое кадров генерируется модулем фракталов Жюлиа FPU. Программный код теста использует расширения и наборы команд MMX, SSE2, SSSE3 или SSE4.1, а также поддерживает гиперпотоковость, мультипроцессоры (SMP) и многоядерность (CMP).
FPU Julia

Этот тест оценивает производительность в операциях одинарной точности с плавающей запятой (32-битная точность) посредством вычислений нескольких фрагментов фрактала Жюлиа. Код для этого теста написан на языке ассемблера, он оптимизирован для большинства популярных вариантов ядер процессоров AMD, Intel и VIA путем применения соответствующих расширений набора команд x87, 3DNow!, 3DNow!+, SSE, AVX, AVX2, FMA и FMA4. FPU Julia поддерживает гиперпотоковость, мультипроцессоры (SMP) и многоядерность (CMP).
FPU Mandel

Этот тест оценивает производительность в операциях двойной точности с плавающей запятой (64-битная точность) путем моделирования нескольких фрагментов фрактала Мандельброта. Код для этого теста написан на языке ассемблера, он оптимизирован для большинства популярных вариантов ядер процессоров AMD, Intel и VIA путем применения соответствующих расширений набора команд x87, SSE2, AVX, AVX2, FMA и FMA4. FPU Mandel поддерживает гиперпотоковость, мультипроцессоры (SMP) и многоядерность (CMP).
FPU SinJulia

Тест оценивает производительность в операциях повышенной точности с плавающей запятой (80-битная точность) посредством вычислений по каждому отдельному кадру с использованием модифицированного фрактала Жюлиа. Код для этого теста написан на языке ассемблера, он оптимизирован для большинства популярных вариантов ядер процессоров AMD, Intel и VIA, позволяет использовать тригонометрические и экспоненциальные инструкции архитектуры x87. FPU SinJulia поддерживает гиперпотоковость, мультипроцессоры (SMP) и многоядерность (CMP).